|
我们离真正的具身产业爆发还有多远?发表时间:2026年03月30日 来源:盖世汽车资讯
在由盖世汽车主办的第四届具身智能机器人产业发展论坛上,行业技术竞逐热烈,但会场内焦虑也在滋生。嘉宾们争相展示自研成果,背后却藏着隐忧:各自为战、闷头布局,有限的资源、稀缺的数据、顶尖的人才,究竟是在推动行业加速,还是在制造巨大的资源浪费?
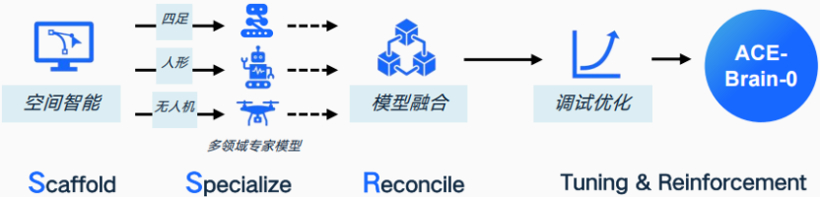
一、数据孤岛:差了一个量级的“数据荒”要让具身模型真正收敛,业内共识是需要至少几百万小时甚至上千万小时的有效数据。据特斯拉Optimus、波士顿动力等海外头部企业公开数据,其核心具身模型训练数据已突破百万小时量级。但千寻智能科研生态总监徐国强直言:“目前国内各家具身智能公司的数据量加起来可能也就几十万小时,距离模型真正收敛,整整差了一个量级。” 更严峻的是,即便数据汇总,质量也难以达标。当前国内数据多集中在机械臂抓取杯子等基础场景,高复杂度、跨场景有效数据占比极低。数据壁垒则加剧困境——数据被视为“核心资产”,各家企业不愿共享。这种状态导致行业重复采集基础数据,造成巨大的社会资源浪费。 转机已在萌芽。国内正推动国家级具身智能数据训练场建设,多所高校已将具身智能专业纳入学科布局,并将数据采集纳入学生日常考评体系。未来数据共享的界限会逐渐被打破。 二、操作系统内耗:等待“一统江湖”的破局者如果说数据是燃料,那么操作系统就是引擎。穹彻智能研究科学家吕峻坦言,当前行业尚处早期,技术未实现跨场景通用,即便单一企业内部,不同交付场景仍需多套OS并行,行业统一更无从谈起。“这不是企业做得不好,本质上是具身智能技术还没达到跨场景规模化应用的水平。” 这与汽车产业早年的电控系统内耗高度相似。早年国内百家车企各自自研电控系统,重复投入、效率低下,最终被域控制器统一、车载OS架构融合的趋势终结。具身智能OS的破局,或可借鉴这一路径:先实现企业内部OS统一,再逐步推动行业层面的兼容与整合。 三、破局路径:开源与整合并行面对困局,国内企业已开始探索破局。2025年12月,大晓机器人发布ACE具身研发范式,构建“环境式数据采集—开悟世界模型3.0—具身交互”全链路技术体系,可实现年千万小时级数据收集,结合数据增强形成等效上亿小时数据训练效果。近期,大晓机器人更将通用基础模型“ACE-Brain-0”面向全行业开源。 这种“基础设施思维”旨在摊薄行业试错成本。大晓机器人解释:“具身智能目前仍处于产业早期,商业化竞争尚未到白热化阶段,当前核心目标是让更多人参与到研发中来,实现资源共享。” 与开源趋势相对照的是垂直整合逻辑。蔚来汽车制造运营中心总监刘圣祥从汽车产线应用端给出务实视角:“我们可以利用开源模型,但最终部署必须是本地部署,训练数据不能出企业。”这是工业场景的核心痛点——产线上的操作数据、工艺参数都是核心商业机密。
四、未来生态:“开源底座+私有数据”的混合形态行业普遍共识是:未来的具身智能生态,既不是纯粹的开源乌托邦,也不是完全封闭的垂直帝国,而是“开源底座+私有数据”的混合形态。基础模型、底层工具链开源,降低行业准入门槛;企业私有数据闭环,保障核心利益和数据安全。这种模式既避免了数据孤岛和OS内耗,又兼顾了商业竞争力。 回到最初的问题:各做各的模型,浪费何时休?答案并不悲观。国家力量正在介入数据训练场建设,头部企业开始尝试开源共享,用户方呼唤既能保护数据主权、又能降低开发成本的新型合作模式。具身智能产业的“临界点”,取决于行业能否在“竞争”与“协作”之间找到黄金平衡点——正如TCP/IP协议成为互联网共识后,才有了万维网的繁荣。这场“浪费”的休止符,将由那些敢于率先打破藩篱的企业来谱写。 |








- 1
- 2
- 3
- 4
- 5
- 6
- 7